Introduction
Nectry is a platform for rapid development of enterprise software without programming. Plenty of competing tools under the headings of “no-code” and “low-code” make similar claims, and here we’ll present Nectry’s technical foundation, which we hope gives a sense of how it is rather different from the competition. Note that Nectry offers a “no-code” view where users need not know almost anything covered in this document! However, for a summary of the underpinnings and to inform more technically inclined users who want the “low-code” view, read on.
In programming classes, we teach students to be very careful about copying and pasting code. It’s easy to propagate a bug across a code base, making it hard to correct the bug when it’s found later. And code full of lengthy copy-and-paste replicas is just plain hard to read, because of how long it gets. The reader is tempted to brush past the apparent replicas, even if they may actually have small differences that affect functionality. The alternative is reading and understanding all of that code each time it comes up, which is rather time-intensive.
In the 21st century, programmers started relying on web sites like StackOverflow to answer their programming questions. So far so good. The trouble is that code snippets are often copied and pasted from these sites, without sufficient understanding that those snippets are really fit for purpose. We get all the same problems of old-school copy-and-paste, and we add the risks of trusting random posters on web sites to give correct answers. Prepare to be creeped out by this quote from a research paper:
Our results are alarming: 15.4% of the 1.3 million Android applications we analyzed, contained security-related code snippets from Stack Overflow. Out of these 97.9% contain at least one insecure code snippet.
Enter AI copilots, starting with the big splash from ChatGPT’s release. They magically write code for you from English requirements! Trade in your coding keyboard for a beach chair and a drink! When AI copilots work well, they effectively automate finding the right snippets to copy and paste together for you. Notice that this variant already brings back all of the downsides we covered above, including introducing bugs from untrusted sources and settling on highly verbose code bases that are hard to read and therefore hard to modify directly. But now we also have the risk that the code was written by a strange alien being (a machine-learning model) rather than just human programmers who accidentally post bad code. The possibilities for crazy bugs are greater than ever – and good luck finding them in long Frankenstein’s-monster code bases full of code snippets adapted from here and there.
It’s undeniable that programming is a tedious and repetitive progress, especially in the world of enterprise software, where each new solution tends to be highly derivative of those that came before. Is there a reliable way we can take advantage of the latest AI advances to streamline development? Nectry embodies one answer!
The Big Idea of Nectry
Software-engineering gurus have been preaching code reuse since dinosaurs walked the earth. Instead of copying and pasting a snippet embodying a good idea, call a library function, allocate an object of a library class, or so on. Give good ideas first-class status in libraries and make them easy to invoke by name. It’s kind of the antithesis of the search-StackOverflow approach. Every popular StackOverflow answer is evidence that some library was missing a nice named component that should have made for a one-line answer!
Nectry leans into this idea and helps programmers build applications solely by choosing, configuring, and composing library components. However, mainstream programming languages don’t have expressive-enough module formalisms to let us write components as high-level as we want. We want full-stack components that stand for complete feature units meaningful to nonprogrammers, like “ticket system.” Such a component should build all code for its feature associated with frontend, backend, and database tiers. Components should be able to adapt to the data models of applications, e.g. a ticket system in a factory might link tickets to rows in a database table of products in the catalog, while a ticket system for a university class might link tickets to rows in a table of homework assignments. Different additional fields might be appropriate for tickets in each context. We should be able to tell the general component which slight variations on its theme we want, and then it generates all of the code for us.
This description probably makes it clear that the approach we’re advocating isn’t a good fit for high-novelty applications, for instance an application worth calling a product. Instead, think of Nectry as more oriented toward internal tools, where a single tool category often exists in moderately different forms across companies. Nectry is also great for creating applications that are used by customers, suppliers, event participants, and more, but we don’t know a good standard phrase like “internal tools” to name this broader category.
The Ur/Web programming language was designed to realize this vision, and UPO (the Ur/Web People Organizer) is a library stocked with components of just the unusual kind we just described. These tools are designed for programmers, supporting programming in a Turing-complete language.
Nectry Builds Low-Code and No-Code Layers on Top of Ur/Web
More technically minded people can write programs in our new configuration language NectryCore, which is very far from Turing-complete, featuring no loops, function calls, or even sequencing of statements. NectryCore configurations just name library components and explain how to put them together into applications, and our compiler and deployment tooling takes it from there.
That’s the “low-code” view of Nectry, but we also support a fully “no-code” view where an LLM-powered chatbot writes the NectryCore code for you, based on conversations in English. More advanced users are always free to look at the generated NectryCore and tinker with it directly, and even less-advanced users can read reliable renderings of NectryCore as English, to spot and correct mistakes with zero trust of AI frontends.
The rest of this document introduces NectryCore by example. We’re going to start with a blank Nectry application, which looks like the following.
A Note on Workflow
Nectry isn’t in public beta yet, and anyone who wants to use it needs to work directly with the company (contact us if interested!). We don’t yet publish any tools for doing anything with the configuration language that this tutorial documents. Instead, we need to set you up in our web-based IDE, which includes a compiler for NectryCore. There will probably be command-line tools eventually for working with NectryCore files.
Think of our NectryCore compiler as producing Docker containers, with standalone web servers inside, that you can deploy wherever you want. The details are largely orthogonal to what is really new and interesting about Nectry, and we don’t bother with them in this tutorial, just presuming that generated web apps pop up somewhere to be used.
Database Tables
Every Nectry application has its own SQL database at its core. We bring other relevant state into that database to connect it to library components. Let’s start by defining a single database table in NectryCore.
items:
- table:
name: Programming Language
columns:
- key: true
name: Name
type: string
- name: Invented in year
type: int
required: trueWe present a standard SQL table schema, just in a funny YAML format. Note that we do not enforce usual rules about names of tables and columns, e.g. our table and column names may contain space characters. These names will often be included for us in UIs that Nectry generates, so it pays to make them approachable for the target user audience of our app.
We have defined a complete NectryCore application, but it doesn’t do anything yet. Let’s create a simple CRUD interface to our one database table, so that we can start with some minimal application functionality. The following code snippet is added after the last one we showed (so the database table remains part of the app configuration).
- handler:
name: main
title: Main
tabs:
- name: Languages
icon: mdi_view-list
segments:
- - module:
name: Languages
concept: Table View
settings:
tab: "Programming Language"Now we have a web app with a single page named “Main,” with a URL ending in main. It includes a navbar that will eventually list multiple tabs of content, though for now we just included one tab. It is labeled “Languages” and lets us view and modify the table of programming languages. We put an icon next to it, referencing one of the icon images from the Material Design framework.
The real action is in invoking one of our library components, which Nectry calls concepts. The one we choose is “Table View,” and we call our instance of it “Languages,” too. It stands for the classic CRUD functionality over one SQL table. In general, concepts may require a variety of settings to explain how we specialize them to our application and data model. Here, we just need to provide one setting called tab, to specify which database table should be shown/edited.
The application now looks like the following (after we use the form to add a few languages), where we can see that the left navbar is used to switch among the tabs listed in a page’s configuration. Each navbar entry has the chosen icon next to it.
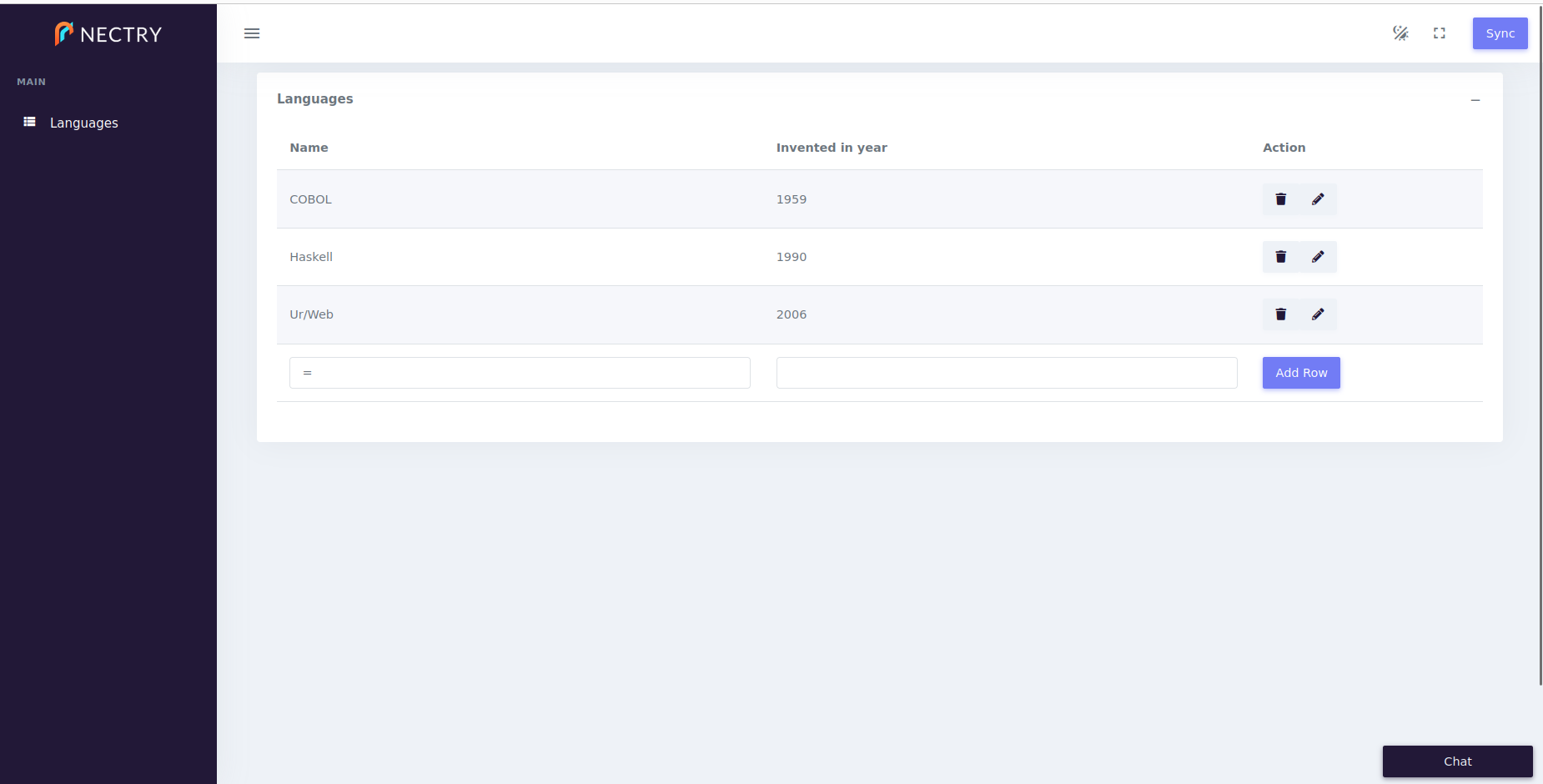
Note that we already have a full-stack web application! We didn’t need to design a single UI or define a single HTTP AJAX endpoint, though both of those aspects are found in the code that is compiled automatically from the NectryCore file. In fact, Nectry does not allow much visual customization in general. We like to say that we adopt the Henry Ford model of user experience (UX): you can have any professional-grade UX you want, as long as it’s the one our team coded into the Nectry component library.
Ingredients
To set up a more complex example, let’s add a new table with the following code right after the table definition in our existing example.
- table:
name: Program
columns:
- key: true
name: Name
type: string
- name: Language
type: Programming Language
required: true
- name: Commentary
type: stringNow we’re storing famous programs, where each has a name, language it’s written in, and optional commentary. Note the type of the Language field: it’s not a base type but a foreign key reference to the programming language it is written in.
Let’s add a form that visitors can submit to tell us about their favorite programs. We’ll use a new important NectryCore element called ingredients. The following code can be added at the end of our configuration.
- name: "Programs"
icon: "mdi_plus-circle-outline"
segments:
- - module:
name: Submit Program
concept: Complex Form Entry
settings:
buttonText: "Add New Program"
tab: "Program"
rowIngredients:
- kind: NormalWidget
settings:
cssWidth: 6
nm: "Name"
- kind: NormalWidget
settings:
cssWidth: 6
nm: "Language"
- kind: NormalWidget
settings:
cssWidth: 12
nm: "Commentary"We have gotten more adventurous, choosing a concept called “Complex Form Entry.” It’s for forms that, upon submission, add entries to tables. In its settings, we say which table tab to submit to, as well as what buttonText to put on the submission button. The new functionality is linked from a new entry in the navbar of the application, with a nice little “plus” icon next to it.
More interestingly, we have some ingredients, or nested invocations of library components of different types, which here we use to specify how different fields of a form should work. We accepted the default behavior of that kind, in our previous use of the more basic “Table View” concept. With “Complex Form Entry,” as the name implies, we have the chance to customize.
Here is the new tab we have designed.
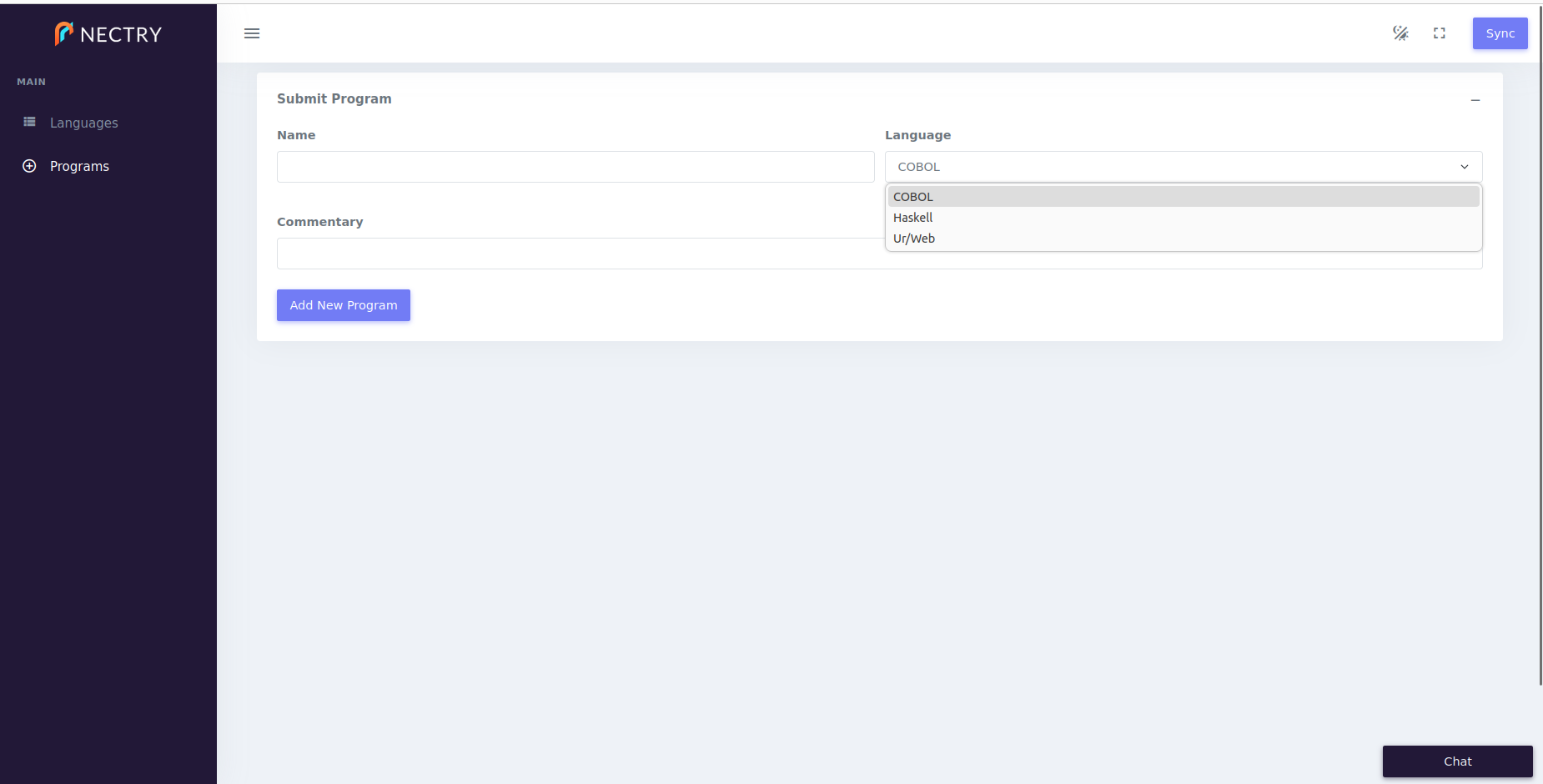
Actually, our use of ingredients here is pretty tame and adds little beyond accepting the default behavior. The foreign-key column “Language” does get treated properly with a dropdown listing all languages in the database, but “Table View” would do that for us, too. Let’s consider how to get more creative specifying behavior of columns.
A realistic scenario is that this app is run by a programming-languages club that is full of snobs. They only want to accept new submissions for classic programming languages, meaning designed before this century. Such a requirement is easily accomplished by editing the ingredient entry for the “Language” column.
- kind: QueryDropdown
settings:
cssWidth: 3
nm: "Language"
query: >-
SELECT "Programming Language"."Name" AS "Id", "Programming Language"."Name" AS "Label"
FROM "Programming Language"
WHERE "Programming Language"."Invented in year" < 2000We use a component called QueryDropdown that runs an SQL query to determine what entries to show in a dropdown. The query appears as a setting here, in Nectry’s funny-looking, work-in-progress query syntax. In general, such a query should give for each entry both its foreign-key value and the appropriate display text to include in the dropdown. Note that the Nectry compiler does type-check this SQL query for us in advance, to guarantee that it never leads to a runtime exception. Indeed, it is even turned into an SQL prepared statement, for maximum efficiency of serving page requests. And as one more advantage of Nectry’s full understanding of SQL, our tooling can warn when a schema change would invalidate existing configuration (or even apply an automatic refactoring to all queries, for simple-enough schema changes).
The dropdown now filters options properly, in addition to including a search box.
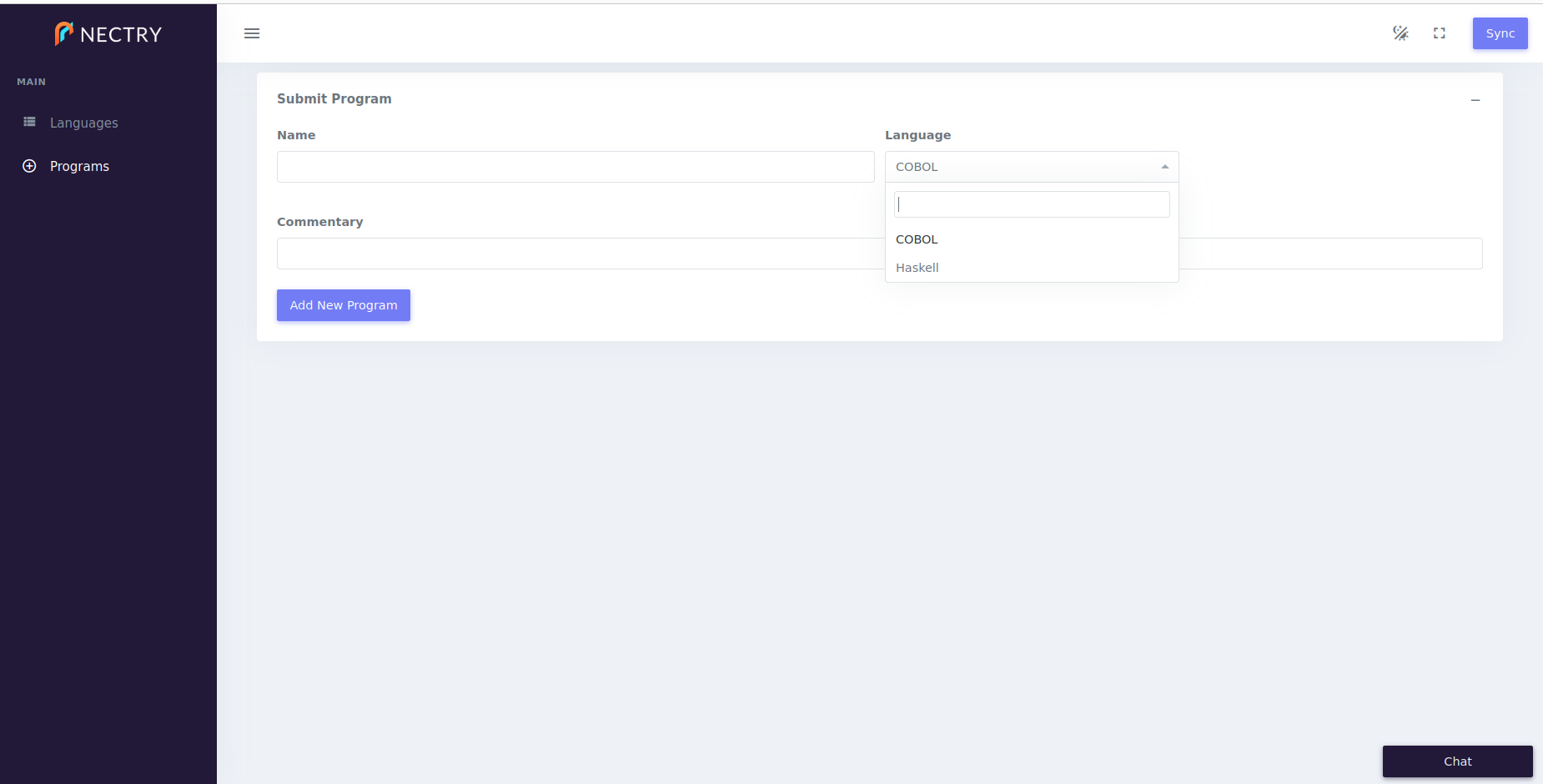
Times and Authentication
Our programming-language club is very exclusive, and we need to authenticate properly to be sure no commoners get in. Let’s add a database table recording authorized users, who of course are invited to declare their favorite programming languages. Let’s also modify the table of programs to record which club member submitted each program.
- table:
name: User
columns:
- key: true
name: Name
type: string
- name: Favorite language
type: Programming Language
- table:
name: Program
columns:
- key: true
name: Name
type: string
- name: Language
type: Programming Language
required: true
- name: Commentary
type: string
- name: Submitter
type: User
required: trueReasonable people will differ on whether it makes sense to include users’ favorite programming languages inline in the table of users, but part of our point here is that Nectry is flexible and allows that schema design choice, among many others.
Now we need to add an authenticator to handle login.
- authenticator:
name: Dummy
provider: Dummy
table: UserThe provider names one of another kind of library component, this time for different ways of logging users in. We’ve built a few for common single-sign-on providers, but for simplicity we stick to a dummy one here, which allows anyone to log in as anyone. An authenticator is connected to a database table of users, which here includes the one with a favorite-language column that the author of the authentication provider certainly didn’t plan for specially. Luckily, authenticators, like other Nectry components, are rather polymorphic in the parts of schemas they are connected to. For this provider, there just needs to be a Name column, and the authenticator will go ahead and add new users as they log in for the first times. (A more industrial-strength authenticator, like for a standard single-sign-on provider, would require that the claimed user actually exist, not to mention that the right password or similar credential was provided!) Note that, for now at least in the design of Nectry, authenticators are a special kind of component, separate from concepts as we used previously.
Now a user faces this logon screen upon beginning a session.
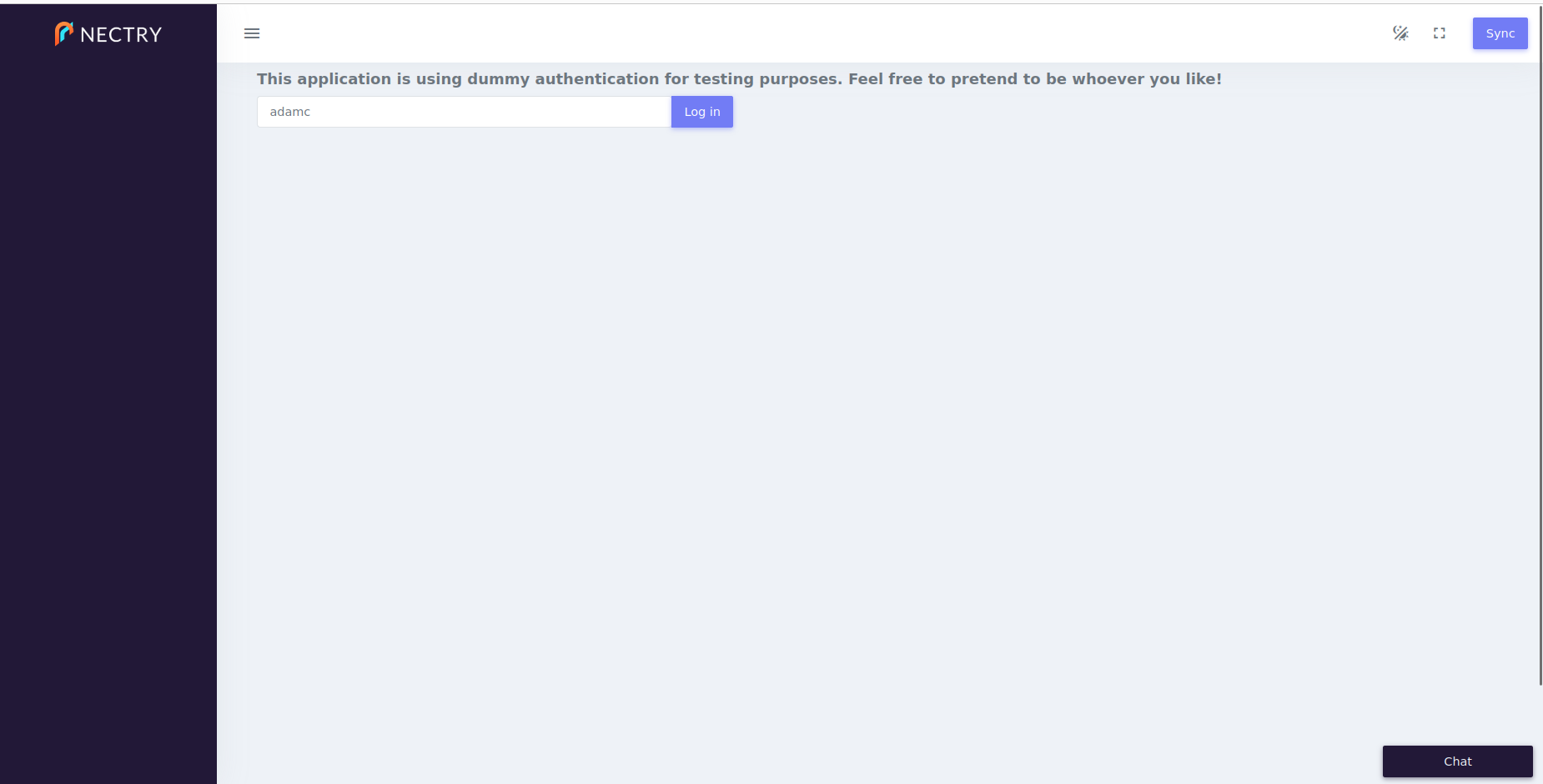
Now here is the modified configuration for our main page handler. See if you can spot the two changes before we describe them next!
- handler:
name: main
title: Main
authentication:
authenticator: Dummy
tabs:
- name: Languages
icon: mdi_view-list
segments:
- - module:
name: Languages
concept: Table View
settings:
tab: "Programming Language"
- name: Programs
icon: mdi_plus-circle-outline
segments:
- - module:
name: Submit Program
concept: Complex Form Entry
settings:
buttonText: "Add New Program"
tab: "Program"
rowIngredients:
- kind: NormalWidget
settings:
cssWidth: 3
nm: "Name"
- kind: QueryDropdown
settings:
cssWidth: 3
nm: "Language"
query: >-
SELECT "Programming Language"."Name" AS "Id", "Programming Language"."Name" AS "Label"
FROM "Programming Language"
WHERE "Programming Language"."Invented in year" < 2000
- kind: NormalWidget
settings:
cssWidth: 3
nm: "Commentary"
- kind: UserField
settings:
nm: "Submitter"We added an authentication field to say that main should require that folks log in via the authenticator we created, and we added a final ingredient at the bottom, for the “Submitter” field of a language. We invoke a UserField component, which automagically fills in this field with the name of the logged-in user. This change doesn’t actually modify the visible UI, so we won’t include a new screenshot.
Note that an authenticator’s login prompt only appears when visiting a page declared as requiring authentication via that authenticator. A visitor can’t see the contents of a protected page without authenticating by the prescribed method.
Let’s show off one more chance to customize form handling. It’s just good bookkeeping to remember when each program was submitted, so we add a column.
- table:
name: Program
columns:
- key: true
name: Name
type: string
- name: Language
type: Programming Language
required: true
- name: Commentary
type: string
- name: Submitter
type: User
required: true
- name: Submitted
type: time
required: trueWe also add one more ingredient at the end of the whole configuration.
- kind: CurrentTime
settings:
nm: "Submitted"At this point you can probably guess what the last snippet is all about! Actually, let us take this opportunity to show off advantages of a nice, structured language like NectryCore. What would happen if we added the following snippet instead?
- kind: CurrentTime
settings:
nm: "User"Oops, we accidentally asked to stash the current time in the User column, which is a type error (type string in the database schema, where time is needed). Not to worry: the NectryCore compiler will warn us of the type error, because it has a thorough understanding of all of the parts of an application.
This stage in the document is a good one for us to explain a larger design principle we’re seeing at work. Many no-code tools will allow configuration of their limited functionality with YAML or JSON files or something. We mean “limited” in a somewhat positive way: by forcing all apps to fit a single model (e.g. spreadsheet-looking UIs), they can limit the design space and more easily achieve good usability. However, Nectry is different in building on an open component architecture that allows developing all kinds of different user experiences and modes of data usage.
Very little that we showed above is built into Nectry. Components like QueryDropdown and CurrentTime, even higher-level concepts like “Custom Form Entry,” can be added without modifying the Nectry engine. They are implemented in Ur/Web and type-checked in isolation, with respect to the formal interfaces that they declare via type signatures. For now, we’re only letting the Nectry engineering team add new components, but we may expose that capability more broadly eventually. Even with just us doing the work to add components, every unit of addition automatically picks up streamlined support in the Nectry development environment.
You can find a variety of examples in the UPO source code, but as just one more level of hand-waving summary: think of each of these components as a class, in the sense of object-oriented programming. For instance, classes QueryDropdown and CurrentTime can be seen as implementing a common interface, with a method for generating HTML for their visual renderings, as well as a method for retrieving the value that has been entered into each. Custom Form Entry “simply” weaves together calls to those methods, to create seamless frontend, backend, and database logic. It isn’t so trivial in practice, since there is fancy static type-checking of components, to make sure they work properly in any scenarios they may be dropped into.
Analytics
It’s easy enough to add other elements like graphing of SQL query results. Here’s all we need to add to graph how many programs are in the database per language, as well as how many programs were submitted per user. We show off including two modules on a single tab. (You may have realized that segments is a list of lists of modules, which in general can be used to describe a two-dimensional grid layout of content.)
- name: Analytics
icon: mdi_chart-bar
segments:
- - module:
name: Program Count by Language Graph
concept: Graph from Query
settings:
query: >-
SELECT "Program"."Language" AS "Programming Language", COUNT("Program"."Name") AS "Number of Programs"
FROM "Program", "Programming Language"
WHERE "Program"."Language" = "Programming Language"."Name"
GROUP BY "Program"."Language"
graphTypeString: "Bar"
- - module:
name: Most Prolific Members
concept: Graph from Query
settings:
query: >-
SELECT "User"."Name" AS "User", COUNT("Program"."Name") AS "Number of Programs"
FROM "User", "Program"
WHERE "Program"."Submitter" = "User"."Name"
GROUP BY "User"."Name"
graphTypeString: "Line"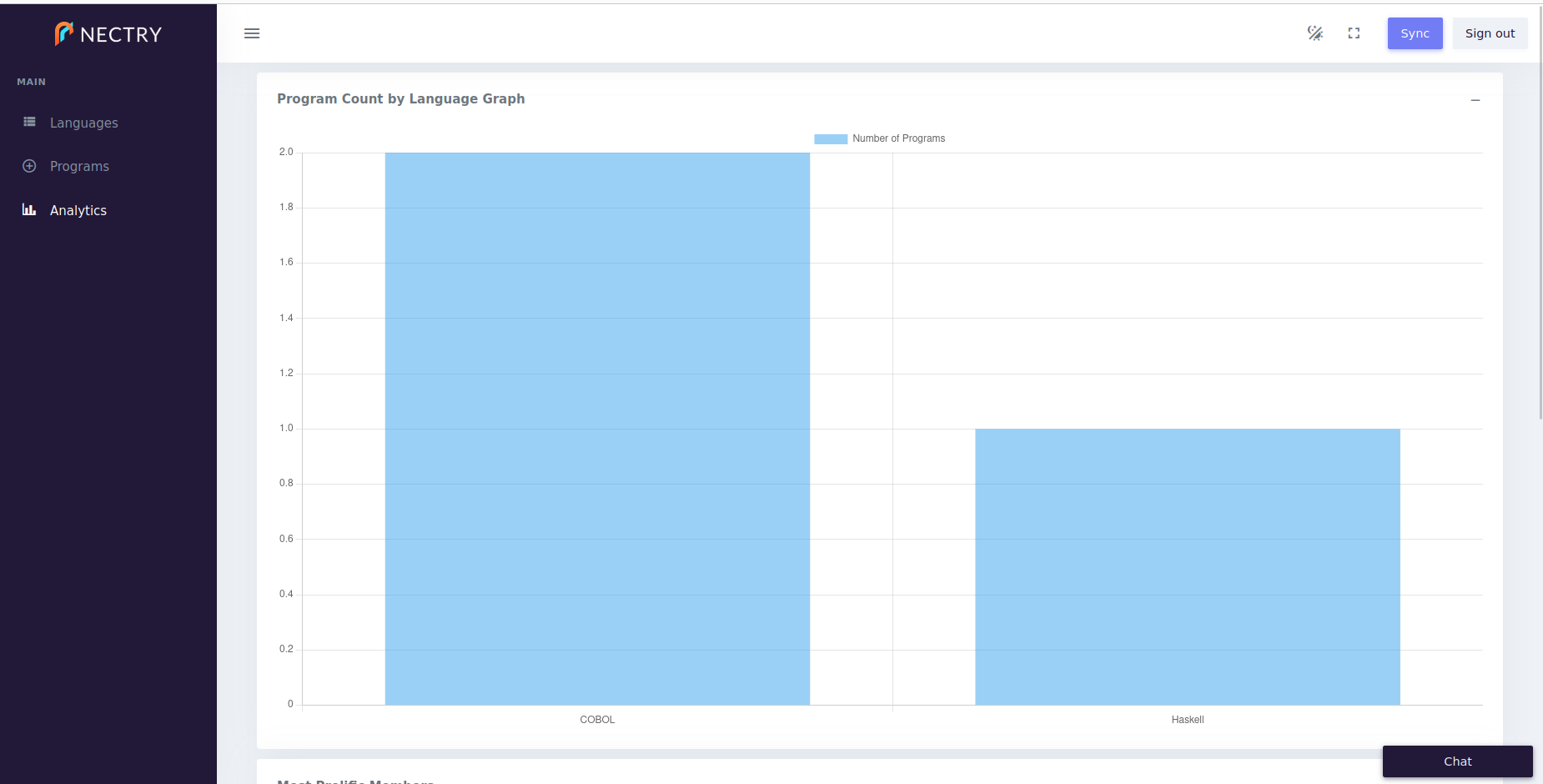
Again, what if we made a small mistake in the code? What if that final snippet were instead the following?
- - module:
name: Most Prolific Members
concept: Graph from Query
settings:
query: >-
SELECT "User"."Name" AS "User", "Program"."Name" AS "Number of Programs"
FROM "User", "Program"
WHERE "Program"."Submitter" = "User"."Name"
graphTypeString: "Line"We forgot to use aggregation, so instead of returning a count of programs, we return program names, which is nonsensical from a graphing perspective. The NectryCore compiler informs us that it really needed to see an int in that position. That is, the compiler parses and type-checks SQL, with respect to the true schema of the application. Sometimes SQL queries even reference NectryCore variables, like those standing for inputs of a page handler, and these parameters are checked with the right types that guarantee consistency within the application.
Data Integration
Entering all of this valuable data over web forms gets old quickly! Let’s create a flow for importing languages from CSV files.
First, recall that Nectry tries to make all the world look like one big SQL database. We create tables in the app’s private database to mirror relevant content from elsewhere in the world. To that end, we make a table to store the contents of an uploaded CSV file.
- table:
name: Imported Language
columns:
- key: true
name: Name
type: string
- name: Year
type: int
required: trueThen we add a new tab to our page, for the UI of importing a CSV file into the new table.
- name: Import Languages
icon: mdi_upload
segments:
- - module:
name: Import CSV to Language Table
concept: CSV Import
settings:
tab: "Imported Language"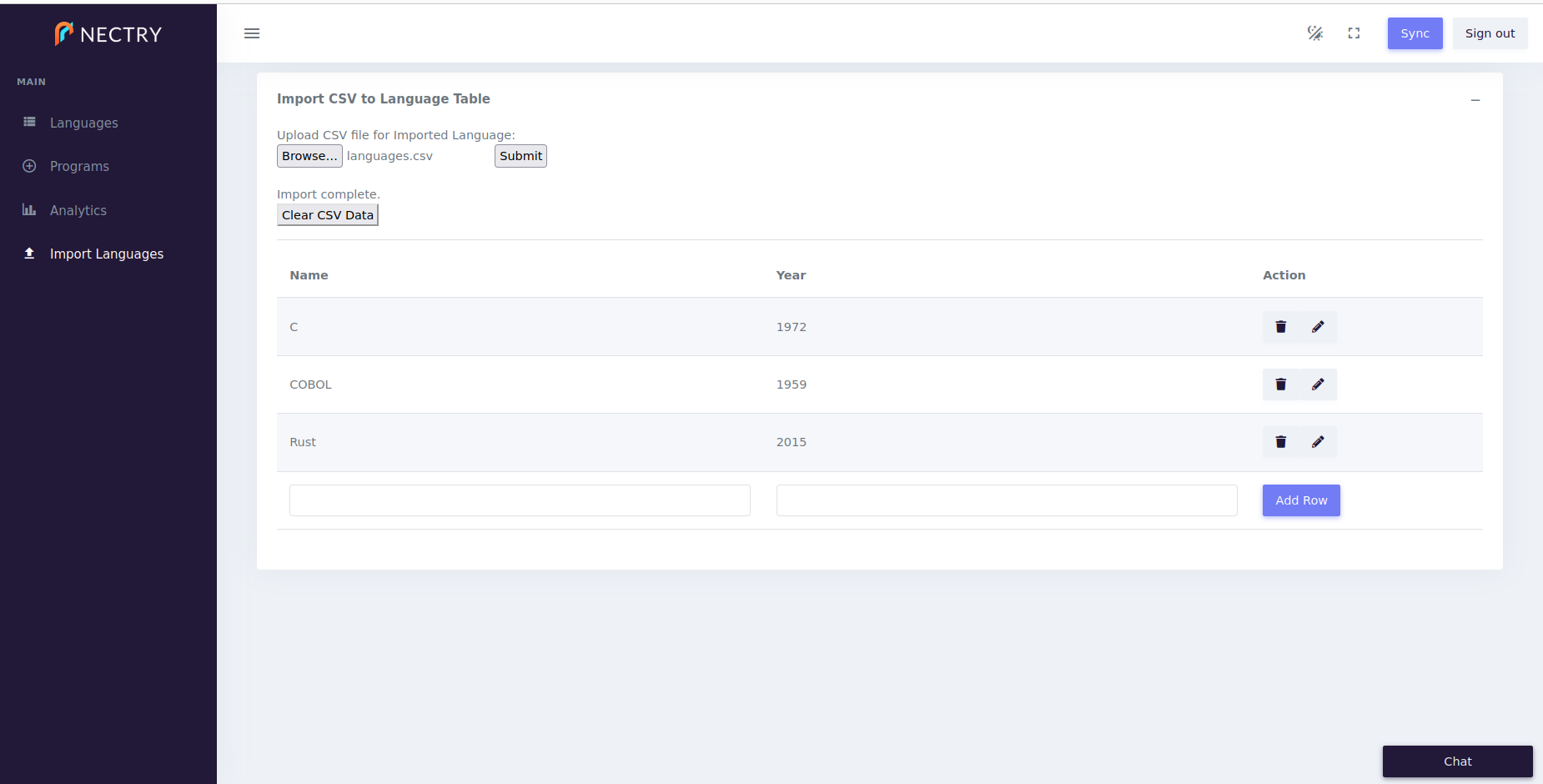
Now, this CSV file came from a dusty old archive somewhere, and we don’t quite trust its contents. There may be languages unbefitting of inclusion in our database, and there may be duplicates of existing languages, with slight spelling differences. Therefore, let’s institute an explicit merging process, to push a subset of these languages into our authoritative table. We’ll simply invoke another concept from our library, in a new segment of the tab we already created for importing languages.
- - module:
name: Copy Imported Data to Main Table
concept: Fuzzy matching
settings:
maxHypotheses: "5"
src: "Imported Language"
dsts:
- kind: OneTable
settings:
default_to_add: true
dst: "Programming Language"
addons:
- kind: AddonWithColumn
settings:
dcol: "Name"
addon:
- kind: FuzzyMatchColumn
settings:
scol: "Name"
- kind: AddonWithColumn
settings:
dcol: "Invented in year"
addon:
- kind: NonMatchingColumn
settings:
scol: "Year"You should be prepared by now to understand most of what is going on in this new example, at least from a structural perspective. On display is the fact that, while NectryCore is intentionally not Turing-complete, it harnesses the full combinatorial power of language to describe complex uses of libraries. Ingredients of one type may have nested ingredients of another type!
Let’s walk through some of the high points of this chunk of configuration. We use a concept “Fuzzy matching,” which generalizes the idea of intelligently copying rows from one table to another. We tell it the source table src is “Imported Language,” which is fed by the CSV-import module we made previously. In general, rows of a given source table could be chosen to copy to a number of destination tables. Hence, “Fuzzy matching” exposes ingredients to explain different strategies of sending results to tables. In this case, we invoke just a single compatible ingredient kind OneTable, where we reveal that the destination dst is “Programming Language.” Then we have nested ingredients explaining how to populate each column of the destination table. Every column gets a use of AddonWithColumn to avoid defining shared settings in multiple places, and then we use a FuzzyMatchColumn to ask that language names be compared for fuzzy similarity to spot duplicates, while a NonMatchingColumn explains that years are merely along for the ride and not compared in duplicate detection. For those of you keeping score at home, that was four levels of nesting of library components of different types!
This new module presents an interface listing all languages we imported, with a suggestion for how to handle each: declare it a duplicate of a particular existing language, add it as a new one, or just skip it. (In general, different behavior could be triggered for the first vs. third of these choices, in more complex uses of fuzzy matching.) The user is free to click to override any choice, before clicking another button to confirm the mass merge.

Connecting to Remote Services
Nectry also makes it easy to connect to name-brand SaaS services (well, at least the ones we already implemented connectors to). Let’s integrate with a Salesforce instance. First, we create two mirror tables that will stand for parts of a remote Salesforce database.
- table:
name: Salesforce Account
columns:
- name: Name
type: string
key: true
- table:
name: Salesforce Contact
columns:
- name: Name
type: string
key: true
- name: Account
type: Salesforce Account
required: true
- name: Email
type: stringNext we configure a service connection to Salesforce, using different kinds of Nectry library components.
- service:
name: Salesforce
provider: Salesforce
api:
provider: Salesforce
settings:
client_id: "HIDDEN"
client_secret: "HIDDEN"
instance: "HIDDEN"
sandbox: false
linkedTables:
- table: Salesforce Account
remoteTable: Account
mode: read_write
kind: Table
- table: Salesforce Contact
remoteTable: Contact
mode: read_write
kind: PersonTableThe occurrences of provider: Salesforce are naming two different kinds of library components: one for APIs, a more primitive notion of connecting to a remote service; and one for services, which brings in the idea of replicating part of the remote database within the Nectry application’s database. Nectry unifies the wide variety of services by making all of them look like subsets of the local database, handling the plumbing of pushing records in both directions as needed. That way, we can use very general full-stack components alongside all kinds of combinations of external services, since they’ve all been made to look like SQL.
The further configuration above provides authentication settings for Salesforce (censored here so you don’t try to hack us!) as well as the explicit linking of remote tables to local ones. Each such linking specifies in which directions data flows (between Nectry app and remote service) with mode fields, as well as tagging each table with a kind, referencing yet another kind of component specific to the service. In this case, we trigger some special savvy for the Salesforce Contact table based on knowing that it represents people, via invoking the PersonTable component.
The point is that, with this configuration set up, Salesforce now looks like just a part of our database, and we can use exactly the same kinds of NectryCore configuration as above, for instance to display tables, graph the results of queries over them, or involve them in data-integration processes that also touch other services’ data.
We should also add that Nectry’s IDE includes a wizard for generating service configuration. The user just picks the name-brand service to integrate and steps through a checklist that we wrote to provision an API connection in that service and copy the relevant authentication fields into Nectry. The IDE also queries the service for its data schema and guides the user through selecting which parts to mirror.
Connecting to Custom Web Services
Suppose our club has a custom legacy web service maintaining a database of programming languages, and we want to import its contents to our new Nectry app. Luckily, there is already a specification for that service lying around, in the quasi-industry-standard format OpenAPI. Here is the API specification. (Don’t get thrown off by the fact that it’s also in YAML syntax. It’s not NectryCore syntax!)
openapi: 3.0.0
info:
title: Programming Languages API
version: 1.0.0
description: A simple API that returns a list of programming languages and their release years.
servers:
- url: http://127.0.0.1:5000
description: Local server
paths:
/languages:
get:
summary: Get a list of programming languages
description: Returns a list of programming languages with their release years.
responses:
'200':
description: A JSON array of programming languages
content:
application/json:
schema:
type: array
items:
type: object
required:
- name
- year
properties:
name:
type: string
example: Python
year:
type: integer
example: 1991OK, so we can perform a GET request to http://127.0.0.1:5000/languages to retrieve a list of programming languages. That should be enough to import the data we need.
In fact, the Nectry IDE includes a wizard wherein we upload an OpenAPI spec and choose how to present the corresponding API as a set of mirror tables. Going through that process, we get the following NectryCore code written for us.
- service:
name: LangDB
provider: Custom
api:
provider: No authentication
endpoints:
- method: GET
url: http://localhost:5000/languages
responseBody:
list: true
type:
record:
- name: name
type:
base: string
required: true
- name: year
type:
base: int
required: true
linkedTables:
- table: LangDB
remoteTable: Languages
mode: read
get:
url: http://localhost:5000/languages
columns:
- remote: name
local: Name
- remote: year
local: Invented in yearNote how the linked-table specification includes a mapping between field names in the API and nicer field names we prefer to work with locally. (Again, it pays off to make them nice because they will appear in automatically generated UIs.)
The wizard also automatically added a table entry (not shown above) for the new LangDB table we define. Now this table is automatically fed from the API, and we can use it just like any of the other tables we’ve worked with. Not shown here is the ability to create read-write table connections, via using other API endpoints (canonically POST) to send new rows to the web service.
Reflecting on Type-Checking
The process we just went through may seem similar enough, on one level, to conventional app development with Python or whatnot, but we’d like to pause here to highlight some key differences. A Nectry app is defined in a unified configuration language, NectryCore, and usually even laid out in a single file. Contrast that state of affairs with using separate programming/template languages for frontend, backend, and database tiers in other frameworks. Not only is it a chore to switch between files in an IDE (if you’re lucky enough to have one that supports all the languages well), but programming tools typically fail to understand cross-language interaction. Even with e.g. all-JavaScript approaches, there is typically minimal help understanding cross-tier interactions up-front.
Nectry is different: every version of the application configuration is statically type-checked to avoid the most common kinds of bugs, security vulnerabilities, and inconsistencies! Here are just a few examples of bugs that can never exist in a Nectry application that passes type-checking. (Some examples draw on NectryCore features that we haven’t yet added to this tutorial.)
- Any HTML or CSS code is invalid.
- Hyperlinks within the application lead to “404 Not Found” errors or subtler errors about missing query parameters or invalid formatting of the parameter values.
- A JavaScript bug leads to failure to look up a node in the DOM or modify it properly.
- A supposed SQL query is sent to the database, but it is syntactically invalid or makes wrong assumptions about the database schema.
- The application frontend calls a backend REST API method that doesn’t exist, or the frontend tries calling the backend method with the wrong number or types of parameters, or the frontend makes a wrong assumption about the type of value returned by the backend.
- The application backend misunderstands the REST API of an external service and makes one of the above errors.
- A cross-site scripting bug allows attackers to submit forms with field values that are accidentally interpreted as HTML, SQL, or JavaScript. (See Little Bobby Tables.)
We aim even higher, by stocking our library only with components that generate high-quality user experience, though we admit this guarantee is much less formal than the above!
What’s Next?
We have some cool security features in mind for Nectry, to check that NectryCore configurations don’t violate information-flow policies. Those features are work in progress and certainly not documented here, but you can check out a research paper that is the intellectual inspiration.
We also hope to have documentation soon on our full library of components, usable in NectryCore configurations.